New Jersey Governor Phil Murphy blamed a shortage of COBOL programmers for the unemployment insurance systems being overwhelmed. Is this really the problem?
After the governor’s statement, there was a lot of press about this shortage of COBOL developers, including an article with the alarming headline “An old programming language is threatening global stability”. In discussing why there is such a shortage, often the blame falls on young developers, who apparently don’t want to work on an old language, and have been attracted by the shiny objects in the newer languages.
Is COBOL threatening global stability?
I know that this is off-topic for the main topic of this blog, but I have worked as a software developer and consultant since 1981. Back in the day I worked at a lot of mainframe sites – I know people who spent their entire career working with COBOL, and I don’t feel that this is a realistic representation of the situation.
Here’s a graph showing NJ unemployment claims from 2008 to 2020:
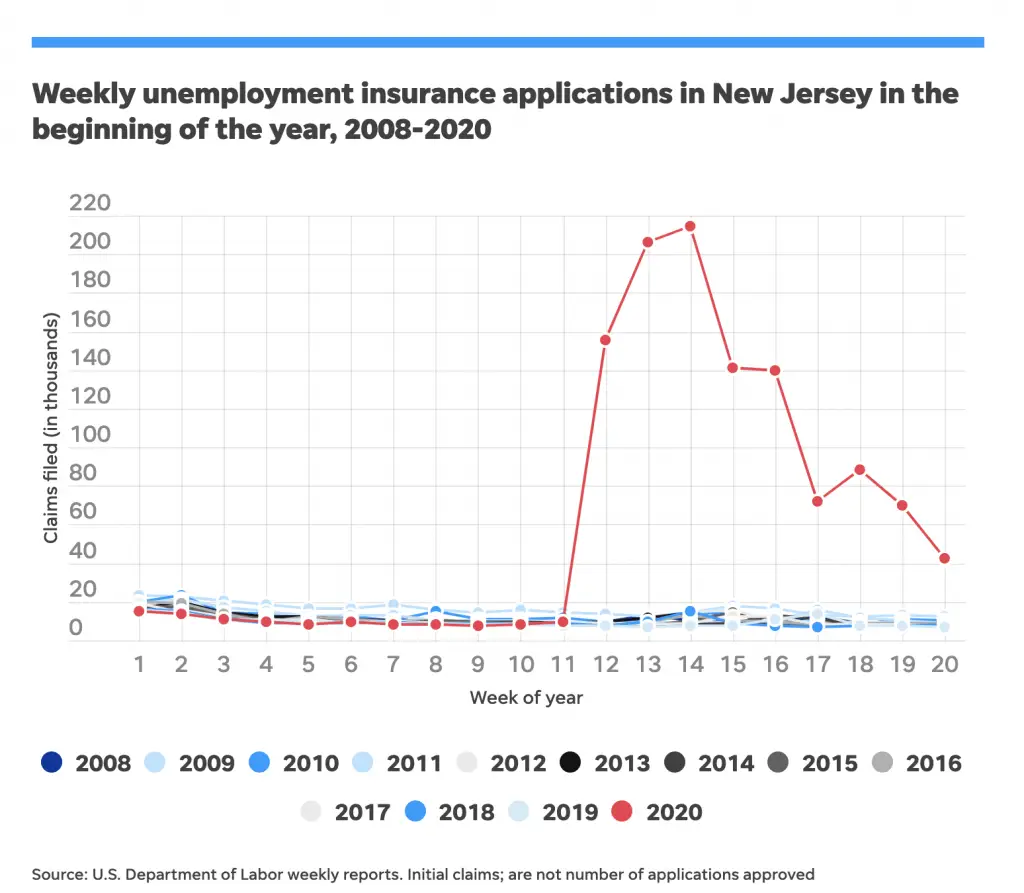
You can see that the NJ unemployment system was perfectly capable of processing around 20,000 claims per week, but in early April 2020 there was a huge spike for five weeks, maxing out at almost 215,000 claims. There are very few computer systems that can handle spikes of ten times the normal volume of traffic, regardless of whether COBOL is involved.
The ‘unemployment system’ here, remember, includes the phone and in-person support to explain how to make a claim, and the paper and online forms to file a claim, as well as the mainframe COBOL application to process the claims.
I know nothing about this specific application, but I’m going to guess that the critical piece involves an overnight batch process. I’m comfortable making such a guess because most large COBOL applications were written with all calculations performed by nightly batch processes. The online data-entry system could be very fast because it left all the calculations to the nightly batch job.
The key with most nightly batch jobs is that you have to shut down online access while you run the batch COBOL jobs. So if your batch jobs have to process 10 times the usual number of records, they might run 10 times longer, and might not be finished by the time you want to bring up the online system. 10 times does not sound so bad, but it could turn a two-hour job into 20 hours. If you cannot bring up the online system, you cannot start to process the next day’s claims, and you get a lot of people shouting.
Would more COBOL programmers fix the problem?
While it is clearly risky to have only one or two programmers supporting a very important application, exactly how could more COBOL programmers speed up a long-running COBOL batch application?
- Could they look over the code, and uncover an error that is causing the program to run slowly?
- Remember that this code has been in use for decades, and has had lots of programmers work on it over the years. I’m sure there is a lot of accumulated technical debt, but I doubt there’s much causing the program to run slowly. So more programmers would simply stand around saying things like ‘that sure is a lot of data you are processing’.
- Could they rewrite the code into a more modern language, like Java or Python, while keeping it on the mainframe?
- COBOL is a compiled language that is extremely fast for most business purposes. Unless you are doing a lot of higher math, for pure speed it is extremely competitive with, or much faster than more modern languages.
- Could they port the system to the Cloud?
- This would solve the scalability issue, but programmers could not port a single part of a large system. This is a big task that would require analysis and careful design to port the entire system (including feeds to all the surrounding systems), keeping in mind privacy issues. This is not a job that programmers alone could solve.
So basically, having more programmers would not make the application run faster.
How to speed up a batch COBOL program?
The way to make a batch application run faster is generally to throw hardware at it. Upgrade the disks, upgrade the CPU, etc.
But upgrading hardware is an expensive ongoing cost, and if you upgrade the hardware so that you can handle 300,000 claims per day, but the claims drop back to 10,000 per day, then you have a large, unnecessary cost.
Wouldn’t it be nice to have the system running in the cloud, where you could just spin up extra power when you need it? I’m sure the services salespeople are lining up (6 ft apart) to make a pitch to state IT departments already.
Why not move COBOL programs to the Cloud?
The trouble is that migrating business-critical mainframe applications to *nix servers is easier said than done (see my post about moving COBOL to the cloud), and many migration projects failed or stalled. Upper management don’t want to invest in the mainframe, but they cannot get rid of it, so they keep the budget as low as possible, and surround the mainframe with other systems to add functionality like a web interface, ad-hoc reporting, etc.
Since the 1990s, there was a general feeling in the industry that the mainframe is dead and that mainframe systems would be rewritten or replaced to run on modern hardware (ie UNIX or Linux servers). I’m not saying this was a universal feeling, or that there were not a significant number of people pointing out how difficult and/or unnecessary this was, but you could certainly see this feeling in the upper management and in the budgets that were assigned to maintain the existing systems.
Coming up to Y2K, there was a concerted push to get as many applications as possible off the mainframe, and after Y2K, as the budgets dried up, the applications that remained were going to stay on the mainframe for some time. Here it is, twenty years later, and yes, they are still running.
Why is there so much noise about a shortage of COBOL programmers?
Well, many mainframe sites have job openings, so it would be reasonable to assume that they are simply unable to find qualified applicants.
However, some US universities still teach COBOL – see this list from Micro Focus. Also, many overseas schools teach COBOL, and when working at companies all over the US, I consistently ran into excellent programmers who had only recently come to the US.
Where are the jobs for junior COBOL developers?
I had a look around on the common job sites, and I did not see any COBOL jobs for junior developers. What I saw were a lot of contract jobs offered for senior developers with 5+ years experience and a long list of ‘required’ skills.
However, look at the pay being offered. Fifteen years ago, six-month contracts to work on mainframes for developer with 5+ years experience were paying $45/hour. It was not considered great pay even then, but it was stable. Today, you find jobs being offered at the same hourly rate as fifteen years ago! The best rate I saw was $60/hour, but they wanted someone with 10+ years experience, and the list of required skills was really extensive.
Just for comparison, a six-month contract for a Java developer with 10 years experience and specific required skills would pay twice as much.
Oh, and the worst thing about the jobs I looked at? They were all strictly onsite – no remote work.
It would be reasonable to assume that developers who know COBOL and who also know other languages, are attracted to jobs that pay better and have more flexible working conditions. There is also the attraction of writing new code and building a skill set for the future rather than poring over huge legacy programs to make minor changes, but new developers could be attracted to the legacy code if the pay was good enough.
I think that the problem is that the core IT organization is taken for granted and under-funded. If companies were truly unable to fill these positions, they would offer more pay, and be willing to hire junior developers with less skills and train them.
I think it is reasonable to assume that the COBOL jobs being offered are eventually being filled, probably with highly-skilled workers recruited from overseas.
Should junior developers switch to learning COBOL?
I hope that junior developers will not get caught up in the hype and train themselves on COBOL thinking they can get a good job, and then get disappointed.
If you want a stable but low-paying job maintaining old code, then a job working on COBOL applications would be fine, but I see no sign that companies are looking to hire junior COBOL developers.
It’s Y2K all over again
Much of the press coverage blaming COBOL for COVID-19 unemployment delays brings up Y2K and surprise that so many systems still run on COBOL. I have seen comments along the lines of “I thought we got rid of COBOL years ago”, and mentions of how this is similar to the Y2K situation.
For those of us who worked on Y2K remediation, it certainly brings back memories – some good, and some bad. A memory that came back to me recently was about one of the “shortcuts” that were taken, which seemed reasonable at the time, but might indeed bring back some of the Y2K problems.
What was the Y2K problem anyway?
A little background: the Y2K (Year 2000) problem that caught everyone’s attention was the widespread use of two-digit years. When applications were being designed in the 1970s, programmers needed to save space everywhere. Disk space was very expensive, so you certainly were not going to keep 4-digit years on fields like birthdates, expiry dates, etc. With millions of rows of data, with a few dates per row, that would add up to megabytes of “wasted” space if every year contained the same two digits ’19’.
This sounds silly now when your phone has 32GB, but in the 1970s, the IBM 3340 (Winchester) disk drive was the size of a washing machine and held two 30MB disks, so yes, it really was necessary to save a few MB on a file.
Two-digit years worked fine when everything was in the same century, with systems doing date calculations like subtracting the birth year from the current year to determine age, etc.
For example, in 1999, you could subtract a two-digit birth year of 80 from a current year of 99, and get the correct answer of 19 years, but in 2000, subtracting a birth year of 80 from a current year of 00 would give -80, rather than the correct answer of 20.
In the 1980s we knew Y2K was coming, but “this program won’t still be in use”
Programmers and IT management knew that by the year 2000 there would be problems IF these programs were still being used, but during the 1980s and even early 1990s, the expectation was that these programs would be replaced or rewritten before 2000.
Preparing for Y2K
During the 1990s, it became common for new programs (and even maintenance on older programs) to use 4-digit years internally, taking the two-digit year from the file and prefixing it with ’19’. This meant that if/when the year fields were expanded in the records, there would be very little change needed in the programs.
Also in the nineties, forward-thinking companies brought in standards stating that all dates used in new files should use 4-digit years, and sometimes went as far as to start expanding date fields any time a change was being made to a file. This sounds simple, but it was a lot of work.
In well-organized sites, there was only one definition of a file’s layout, in a shared copybook, so when you expanded a year field in the copybook, you had to find and checkout every program that used that copybook, write a conversion routine to update all the records in the file, then compile and test every program. There were often programs that did not even use the date fields at all, but they would still have to be compiled and tested because the length of the record had changed or fields had moved. Then all this work had to be tested extensively before being scheduled to move into production.
This was a lot of work even in well-organized sites, and when there were multiple copybooks or local inline copybooks it was a lot more work. This effort was impossible to justify within a regular maintenance budget.
Why did the Y2K problem not get fixed earlier?
Since the task could not be justified as maintenance, many companies gave this task its own budget, but many did not.
There were various reasons – they were planning to migrate to a purchased package, or to rewrite the entire application, or there was another reason why the application was only expected to be used for another couple of years, etc. In any case, they did not see a reason to update code which would be going away before the year 2000.
Of course, quite a few of these migration or rewrite projects failed or did not get funded, and the code kept on running in production.
A worrying time for management
Around 1995, IT management started to get very worried. They called in consultants to perform audits and develop action plans. They prioritized purchasing packages to replace old systems, or migrating to relational databases.
Still, by 1998 or 1999 some companies realized that some of these replacement or migration projects were not going to be finished by 2000, and they were staring at a hard date and they simply did not have enough time to do the work and testing to expand all the date fields in all the files.
Was there a shortcut to handle Y2K?
What to do? In companies all over the world who were facing this problem, the same solution was proposed. Since most programs already used 4-digit years (CCYY) internally and just hard-coded CC to ’19’, they just needed a bit of logic to set the first two digits (CC) to either ’19’ or ’20’. There was enough time to retrofit this kind of code into all the programs that used dates.
There would be no need to change the record lengths, so programs that did not actually use the dates could be left alone.
As a side note, most developers used the term ‘century’ for the high-order two digits (CC). Yes, most developers knew that 1999 was part of the twentieth century, while 2001 was in the twenty-first. For some reason ‘century minus one’ never caught on as a name for this field.
How to decide when to set the century as ’20’?
This could be different for each year field, depending on what data it carried: if the date was a birthdate and the oldest person in the file was 75 years old, then you could safely assume that any two-digit year from ’25’ to ’99’ should start with ’19’, and from ’00’ to ’24’ should start with ’20’. That would allow the two-digit field in the file to represent a 100-year window from 1925 to 2024.
If the date was to do with a policy or a loan, and the company had no documents prior to 1950, then you could use the same logic to represent a 100-year window from 1950 to 2049.
In meetings at many companies, this shortcut was approved as a short-term fix, which would buy time to complete the migrations to other systems or databases. Brilliant, everyone would say – let’s write this up, hire some contract programmers, and get moving! A joker would often pipe up “hey – I sure hope this system gets replaced soon after 2000”, and everyone would laugh.